

Begin augustus 2021 verscheen de blog Dutch Prize Papers. In het ‘Prize Papers’ archief van The National Archives te Kew (Londen) wordt een zeer gevarieerde collectie van scheepspapieren en correspondenties bewaard: de prijs van Britse kapers uit de periode 1652-1815. In juni 2019 kwamen op Dutch Prize Papers 72.000 scans of 140.000 bladzijden van vooral Nederlandse documenten uit de zeventiende tot begin negentiende eeuw en hun metadata online beschikbaar. De blog vertelde over de start van een proef voor automatische tekstherkenning van handgeschreven documenten (bekend als Handwritten Text Recognition – HTR) met behulp van het artificiële intelligentie–platform ‘Transkribus’. Met de recente, belangrijke verbetering van tekstherkenning door toepassing van nieuwe software is het moment daar om “U hoort ervan!” – aan het einde van deze eerste blog – na te komen.
Verkenning met ‘Transkribus’
De 1.000 scans die we (het projectteam) in ‘Transkribus’ plaatsten, splitsten we in een groep ‘hoofdzakelijk handmatig’ (100 scans) en een groep ‘vooral automatisch’ (900 scans). Met de eerste groep gingen we aan de slag. We selecteerden 100 scans zeventiende tot negentiende-eeuws schrift in verschillende talen, die we naar de zogeheten ‘Ground Truth’-status moesten brengen. Ground Truth is een zo correct mogelijke kopie in machineschrift van de originele tekst. Zo’n kopie ligt aan de basis voor training van een HTR-model; een onjuistheid in de kopie betekent minder goede machine learning. Aan de Ground Truth-status van een tekst gaan twee grote handelingen vooraf: lay-outanalyse en transcriptie.
Lay-outanalyse houdt het markeren van regio’s en lijnen binnen een tekst in. Een regio is bijvoorbeeld een datum of alinea. Lijnen die direct onder de schrijfregels (de zogenoemde baselines) moeten worden getrokken, dienen als referentiepunten voor het transcriberen en trainen. Een speciale tool is in ‘Transkribus’ beschikbaar om lijnen automatisch onder de schrijfregels te laten plaatsen. Aangezien tekstregels in ‘Prize Papers’ vaker scheef dan recht en vaker niet dan wél aaneengesloten lopen, was de lay-outanalyse vooral handwerk.
Op de geannoteerde lay-out volgt de stap van de transcriptie. Gelukkig konden we voor een basistranscriptie profiteren van beschikbare taalmodellen per eeuw, bijvoorbeeld de (Nederlandse) IJsberg en Republic_7 modellen. Een basistranscriptie kan helpen bij het herkennen van woorden. Zij vergemakkelijkt en versnelt ook de noodzakelijke handmatige correcties om uiteindelijk de Ground Truth-status te bereiken.
De Ground Truth-scans werden ingezet voor training. We maakten hiermee een Dutch Prize Papers-model, waaraan het basismodel IJsberg voor extra trainingsmateriaal werd toegevoegd (DPP 1). Om te kunnen vergelijken, maakten we bovendien een Dutch Prize Papers-model zonder de toevoeging van een basismodel (DPP 2).
Met de ontwikkeling van twee meertalige modellen op het ‘Transkribus’-platform verkenden we mogelijkheden van automatische tekstherkenning, het hoofddoel van de proef. We probeerden uit hoe bruikbaar ‘onze’ modellen in vergelijking met andere zijn en kregen verschillende transcriptieresultaten. Hieronder een voorbeeld van een achttiende-eeuwse schriftregel. R betekent Republic_7, IJ is het IJsberg model, P1 en P2 staan voor Dutch Prize Papers 1 (inclusief IJsberg) en Dutch Prize Papers 2, H betekent handmatig.
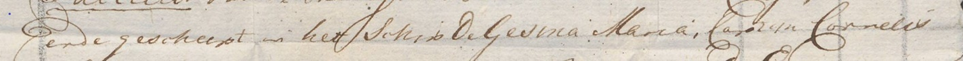
R-De rescheept in heff schip deGesna Mara, Carran Cecrelis
IJ-ende gescheept in hetschip de Gesina Maria, Camjn Cornelis
P1-ede gescheept in het Schip de Gesina Mana, Comyn Cannelis
P2-Dene gescheept en her Schip de Gesena Aana, Comin Corneeir
H-ende gescheept in het schip De Gesina Maria, Captyn Cornelis
Een specifiek automatisch model dat de meest foutloze transcriptie geeft, springt er niet echt uit. Het projectteam besloot in april 2022 de balans op te maken en de hoofdvraag erbij te pakken : “wat zijn de te verwachten resultaten voor de tweede groep, de 900 scans, die grotendeels automatisch gegenereerde transcripties zouden moeten krijgen en – uiteindelijk – voor de rest van de collectie van 72.000 scans?”
Toepassing van ‘Loghi’
Veel handschriften en meertaligheid in een ingewikkeld en niet eenvormig bestand als de ‘Prize Papers’, betekenen een grote tijdsinvestering in het maken en controleren van lay-out. Geen correcte plaatsbepaling van tekstregels betekent immers een minder goed HTR-resultaat. Ook het verder verbeteren van het Dutch Prize Papers 1-model door de aanlevering van meer trainingsmateriaal is tijdsintensief. Na de opstelling van een positief evaluatieverslag besloten we de proef toch te stoppen en te wachten op de aanstaande beschikbaarstelling van nieuwe transcriptie-software voor handgeschreven en gedrukte teksten, ontwikkeld door het ‘KNAW Humanities Cluster’. Onder de naam ‘Loghi’ kwam de software in april 2023 volledig open beschikbaar.
‘Loghi’ kan hetzelfde als ‘Transkribus’ – namelijk het transcriberen van documenten – en is in het bijzonder geschikt voor toepassing op hele grote bestanden. Een lay-outanalyse tool, de eerste essentiële stap, is in het pakket opgenomen. Voor het gebruik van deze gratis transcriptie-software is echter wel enige programmeerkennis nodig.
Met de toepassing, eind juni 2023, van het nieuwe tekstherkenningsmodel ‘Loghi’ op alle Dutch Prize Papers zijn de leesbaar- en doorzoekbaarheid van de documenten flink vooruitgegaan. In het trainingsmateriaal van ‘Loghi’ zijn ook de 100 ‘Ground Truth’ scans verwerkt. De transcriptie van de regel in het hierboven geïllustreerde voorbeeld is nagenoeg correct: Eerde gescheept in het Schip de Gesina Maria, Carijn Cornelis. Een mooi resultaat.
Teneinde de Dutch Prize Papers verder en breder toegankelijk te maken, namen we in het evaluatieverslag de aanbeveling op dat doel per documenttype aan te pakken, te beginnen met cognossementen (vrachtbewijzen).
Documenttype: cognossementen

Het hierboven getoonde cognossement, uit de ‘West’ en zeventiende-eeuws, laat zien dat dit type document informatie genereert over goederen, personen (vervoerders, afzenders en ontvangers van vracht), schepen en scheepsroutes (havens van vertrek/bestemming of laad- en losplaatsen). Na afhandeling van vervoer van vracht over de zee werden cognossementen meestal niet langer bewaard; in de ‘buit’ van Britse kapers vinden we ze terug.[1] Het zoeken in Dutch Prize Papers via Text Search naar het specifieke woord ‘overloop’ (het afsluitdek van een vrachtruim op een schip), levert nu meteen heel veel cognossementen op.

Ook via het Oldenburgse Prize Papers portal is een omvangrijk corpus toegankelijk.
De door ‘Loghi’ verbeterde basistranscripties vergemakkelijken nu de invoer van alle informatie in een hiervoor opgezette database.
Cognossementen zijn een waardevolle bron voor het in kaart brengen en visualiseren van overzeese handelsstromen en netwerken. Op de website van het ‘Huygens Instituut’ staan vergelijkbare bronnen over goederenstromen, denk aan de Boekhouder-generaal Batavia, Dutch-Asiatic shipping en Sonttolregisters. In het kader van het koppelen van maritieme gegevens uit verschillende collectiesystemen en van instellingen is het Netwerk Maritieme Bronnen vermeldenswaard; gegevens omtrent dit netwerk in wording zijn uiteraard op het ‘Maritiem Portal’ te vinden.
Biografie
Marijcke Schillings is onderzoeker binnen de onderzoeksgroep ‘LivesLab’ van het Huygens Instituut – KNAW. Zij coördineert Dutch Prize Papers sinds de start van het project in 2016.
Met veel dank aan Rutger van Koert, Jelle van Lottum, Ronald Sluijter, Marja Swüste voor de samenwerking en Sebastiaan Derks en Annemieke Romein voor advies tijdens deze proef van automatische tekstherkenning.
[1] Zie bijvoorbeeld hierover: “Flessen op papier”, A.P. v[an] V[liet], in : Buitgemaakt en teruggevonden. Nederlandse brieven en scheepspapieren in een Engels archief. Sailing Letters Journaal V. Onder redactie van E. van der Doe, P. Moree, D.J. Tang, met medewerking van P. de Bode (Zutphen 2013) 196-197.